
 Ruku v ruce s rozšiřujícími se schopnostmi koncových zařízení začíná mnoho vývojářů embeddeded systémů logicky ustupovat od procesorů s jedním jádrem a zaměřovat se spíše na vícejádrové struktury. Pouze vícejádrové procesory totiž mohou uspokojit současné požadavky v otázce dosahovaných parametrů, vzrůstajícího výpočetního výkonu, robustního provedení a také nižší ceny. Vývojoví pracovníci, přecházející k multijádrovému přístupu, budou pravděpodobně čelit určitým obtížím, ale výhody, kterých takto nakonec dosáhneme, se rozhodně vyplatí!
Ruku v ruce s rozšiřujícími se schopnostmi koncových zařízení začíná mnoho vývojářů embeddeded systémů logicky ustupovat od procesorů s jedním jádrem a zaměřovat se spíše na vícejádrové struktury. Pouze vícejádrové procesory totiž mohou uspokojit současné požadavky v otázce dosahovaných parametrů, vzrůstajícího výpočetního výkonu, robustního provedení a také nižší ceny. Vývojoví pracovníci, přecházející k multijádrovému přístupu, budou pravděpodobně čelit určitým obtížím, ale výhody, kterých takto nakonec dosáhneme, se rozhodně vyplatí!
Přechod od jednoho jádra k multijádrovému systému vyžaduje nové přístupy včetně nezbytného povědomí o tom, jak spolu budou jednotlivé části souviset a také spolupracovat. Prvky, využívané při běhu programu v multijádrových strukturách, navíc sdílejí periférie a proto bude optimální využití těchto periférií v otázce udržitelnosti výkonu klíčové.
Setkáváme se zde, celkově vzato, se dvěma skupinami vícejádrových procesorů, odlišených použitými architekturami. Jedná se o homogenní (stejnorodé) vícejádrové procesory a heterogenní (různorodé) vícejádrové procesory. V případě homogenního vícejádrového procesoru hovoříme o dvou nebo více shodných, programovatelných jádrech, sdílejících periférie a také paměť. Pod označením heterogenní procesor zase rozumíme vícenásobné, jedinečné elementy, z nichž každý byl přizpůsoben k vykonávání specifické funkce, přičemž každé jádro pravděpodobně získalo pouze selektivní přístup k perifériím a také paměti.
Vývojáři, pracující s homogenními či heterogenními multijádrovými systémy, musí věnovat pozornost dvěma skupinám problémů: Synchronizaci a časování, resp. všemu okolo výkonu.
Multijádrové architektury se zaměřují na systém a jeho integraci. Rostoucí počet jader se odrazil ve zvýšené míře integrace v souvislosti s perifériemi, sběrnicovými strukturami a také víceúrovňovými paměťmi. PE (Processing Elements) zase v multijádrových systémech zajišťují část funkcí daného obvodu. Ve spojení s vylepšeným kódováním, pouzdřením a také postupy během samotné integrace zůstávají tradiční ladicí techniky, jako např. synchronní run, step nebo halt, i v případě vícejádrových systémů docela efektivní. Budou – li však procesy interagovat, začnou otázky, spojované s časováním nebo synchronizací, představovat problém.
Potíže, spojované s časováním nebo synchronizací, vyplývají ze závislostí mezi PE. Vše je navíc mnohem složitější kvůli sdílené podstatě systémových periférií, sběrnicových struktur nebo víceúrovňových pamětí. Díky závislostem mezi PE může v souvislosti s procesy a jejich vzájemnými vztahy docházet k chybám, neefektivitě či problémům, které mohou být velmi rafinované. Takové, sotva patrné komplikace přitom patří z hlediska jejich detekce, vyčlenění a nápravy k těm nejvíce obtížným. Tak například v rámcově orientovaném systému možná propásneme rámec, protože zpracování nebylo v daném čase dokončeno. Taková aplikace přitom nemusí spadnout, ale její výsledky již mohou být touto okolností poznamenány – možná pozorujeme jeden rámec nižší kvality z tisíců dalších. Příčina těchto potíží s časováním může spočívat v nedostatku výpočetního výkonu, kolizi nebo čekání na sdílené systémové periférie, sběrnici či paměť. Případné vyčlenění takových problémů proto bývá docela náročné. Při optimalizaci a ladění činností vícejádrových systémů, souvisejících s jejich časováním nebo synchronizací, budou proto rozhodující nástroje, nasazované na úrovni samotného čipu, pronikající do souvislostí mezi PE a systémovými perifériemi, sběrnicí a také pamětí.
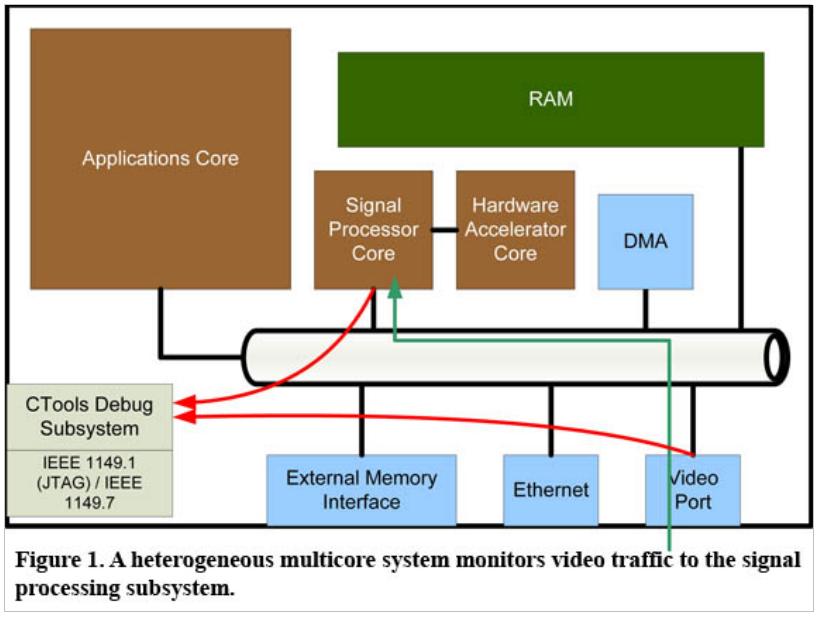
Vícejádrové systémy se skládají z četných vrstev. Budeme tedy potřebovat stejně četné úrovně viditelnosti, přičemž každá úroveň vývojářům skýtá příslušný stupeň dohledu a také řídicích schopností. Na nejvyšších úrovních pak bývá vyžadován dohled nad samotným čipem. Měli bychom tak být schopni vizualizovat vzájemné působení mezi PE a klíčovými perifériemi. Vedle toho, že uvidíme vzájemné interakce mezi PE, bude k optimalizaci výkonu rovněž přispívat klíčová schopnost najít vztah mezi výkonností zásadních periferních rozhraní a úlohami na PE. Korelace (vzájemný vztah) událostí s přesnou časovou značkou umožní vývojářům v případě čipové úrovně a souvisejícího náhledu účelově rozpoznat a optimalizovat potřebné výkony. Uživatel může např. rozlišit časování datových přenosů mezi PE. Jindy zase rozpoznáme výkonnostní bariéry, definované použitou strukturou, a můžeme tak optimalizovat celý vícejádrový systém.
Na další úrovni lze pracovat s ještě podrobnějším náhledem, zahrnujícím přezkoumání a také modifikaci paměti nebo příslušných nastavení, resp. trasu každé instrukce, vykonané PE. Skvělý stupeň granularity, zajišťované prostředky procesoru, usnadňuje uživatelům optimalizaci a také ladění jejich softwaru, zatímco poběží v real – time systému na plné rychlosti. Simulační prostředí přitom často mívají problémy v souvislosti s větším počtem přerušení a mezisystémovými interakcemi.
Optimalizace multijádrových systémů bude v budoucnu patřit k nejdůležitějším úkolům vývojáře. Abychom tedy mohli začít využívat obrovský výpočetní potenciál vícejádrových obvodů, budeme muset proniknout do podstaty synchronizace a časování mezi PE a perifériemi a také pochopit výkonnostní překážky a omezení mezi PE, systémovými perifériemi, sběrnicovými strukturami a víceúrovňovými paměťmi. Nové, multijádrové procesory budou vedle toho ještě vyžadovat robustní nástroje, pracující na úrovni samotného čipu, které zajistí četné úrovně viditelnosti a pomohou tak vývojářům plně využít dostupný výkon.
![]() Něco o autorovi:
Něco o autorovi:
Stephen Lau v TI odpovídá za definice technologií pro on – chip ladění a také související emulační produkty, nasazované prostřednictvím komunity vývojářů třetích stran. Rovněž má na starosti marketing v souvislosti s IEEE 1149.7 a také první komerční IP licenci TI pro ladicí technologie. Je držitelem bakalářského titulu v oblasti elektrického inženýrství, získaného na McMaster University (Hamilton, Ontario, Canada).



